Spark Performance Optimization Series: #1. Skew
4.5 (495) · $ 17.50 · In stock

In Spark cluster data is typically read in as 128 MB partitions which ensures even distribution of data. However, as the data is transformed (e.g. aggregated), it is possible to have significantly…
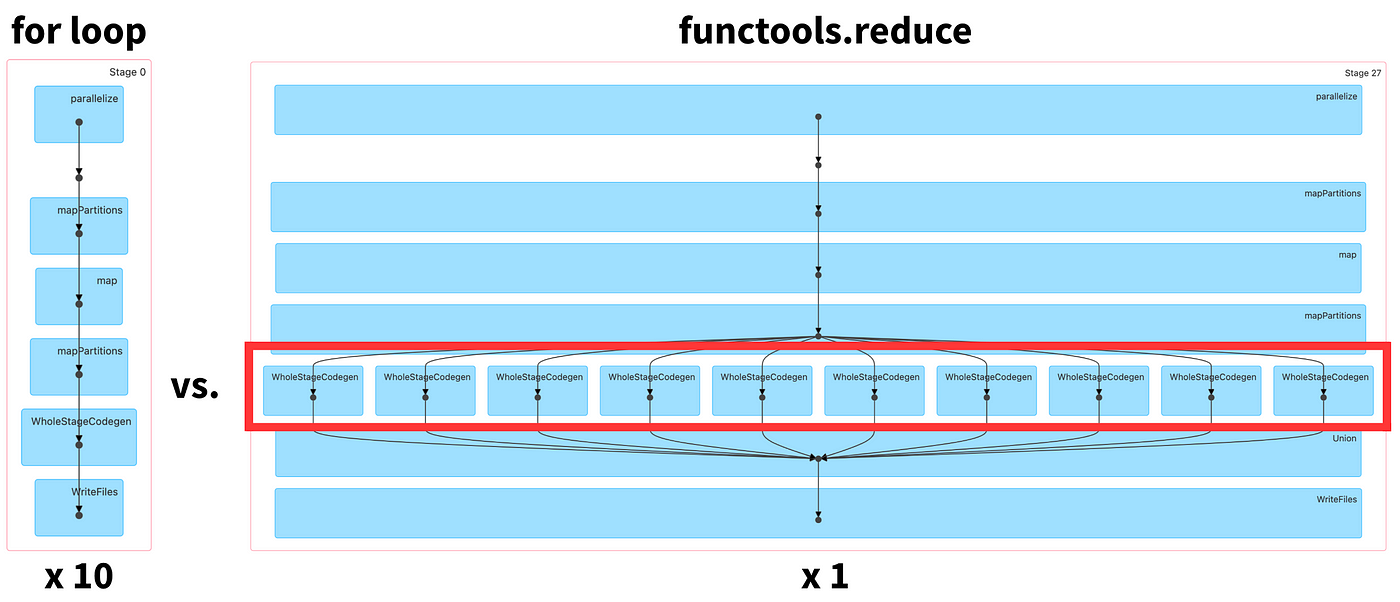
1.5 Years of Spark Knowledge in 8 Tips, by Michael Berk
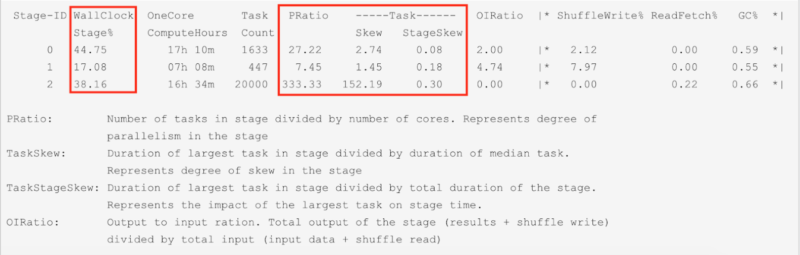
Spark Application Optimization for Performance using Qubole Sparklens

How to Optimize Your Apache Spark Application with Partitions - Salesforce Engineering Blog
List: Apache Spark, Curated by Luan Moreno M. Maciel

Apache Spark Structured Streaming and left outer join bug fix

Monitoring Apache Spark – We're building a better Spark UI - KDnuggets
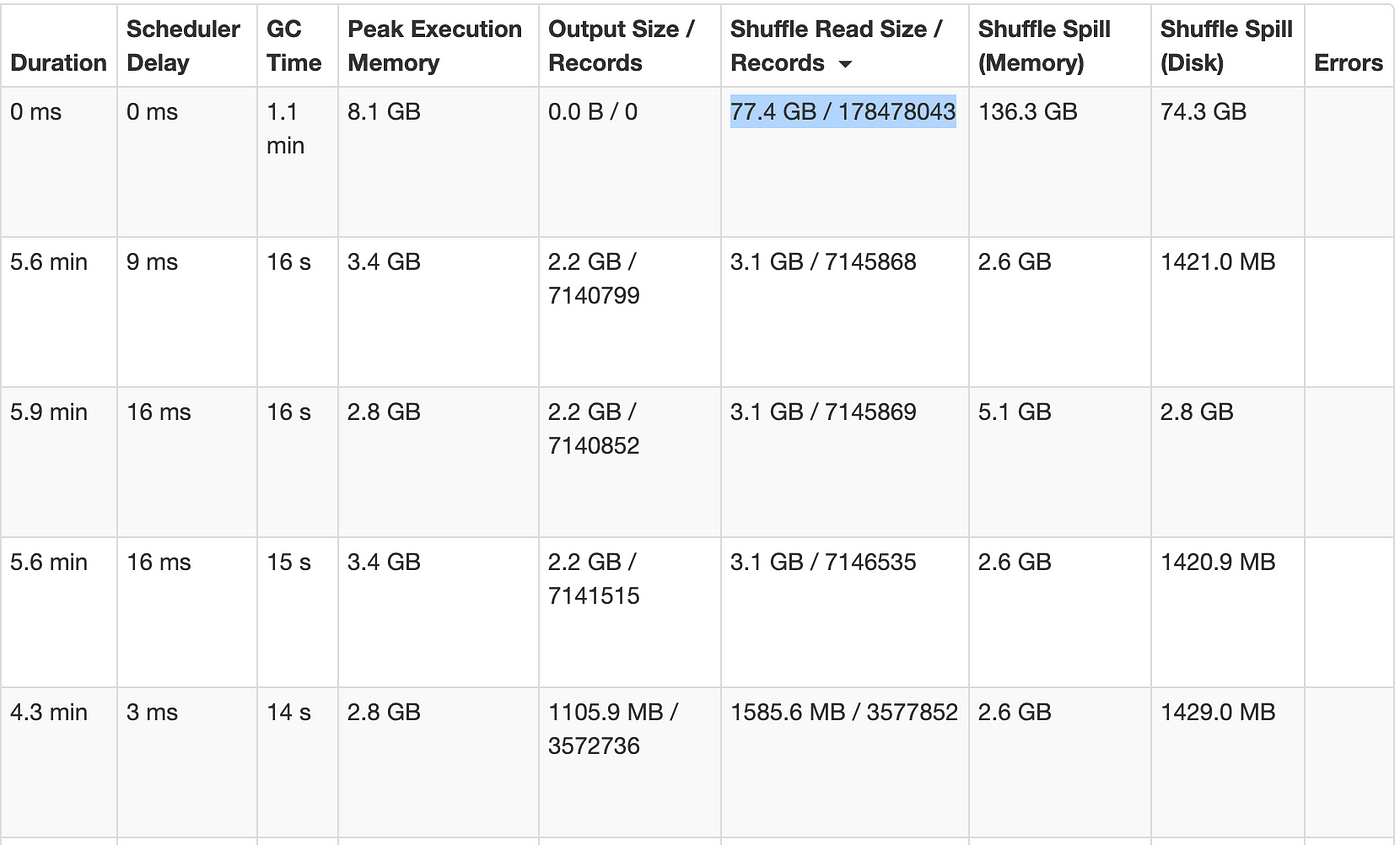
Handling Data Skew in Apache Spark, by Dima Statz

Scalable algorithm for generation of attribute implication base using FP-growth and spark
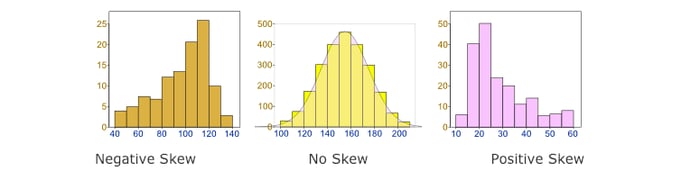
Optimizing the Skew in Spark

Spark Performance Optimization Series: #1. Skew, by Himansu Sekhar, road to data engineering
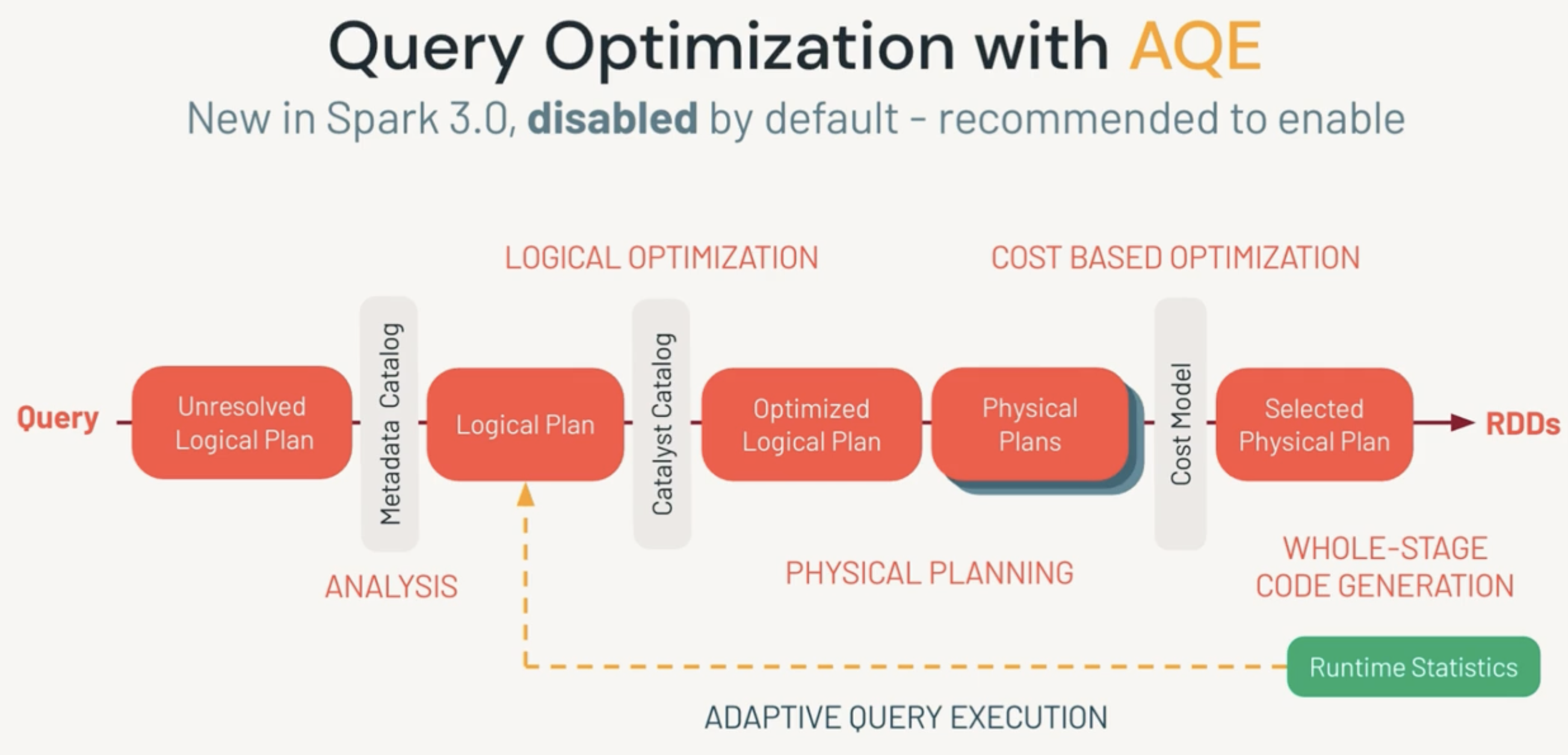
Spark working internals, and why should you care?

Spark Performance Tuning: Skewness Part 1, by Wasurat Soontronchai

Spark Performance Tuning: Skewness Part 1, by Wasurat Soontronchai











